This is a brief aside from my ongoing series about avoiding entity services. An interesting dinner conversation led to thoughts that I needed to write down.
Amdahl's Law
In 1967, Gene Amdahl presented a case against multiprocessing computers. He argued that the maximum speed increase for a task would be limited because only a portion of the task could be split up and parallelized. This portion, the "parallel fraction," might differ from one kind of job to another, but it would always be present. This argument came to be known as Amdahl's Law.
When you graph the "speedup" for a job relative to the number of parallel processors devoted to it, you see this:

The graph is asymptotic in the serial fraction, so there is an upper limit to the speedup.
From Amdahl to USL
The thing about Amdahl's Law is that, when Gene made his argument, people weren't actually building very many multiprocessing computers. His formula was based on first principles: if the serial fraction of a job is exactly zero, then it's not a job but several.
Neil Gunther extended Amdahl's Law based on observations of performance measurements from many machines. He arrived at the Universal Scalability Law. It uses two parameters to represent contention (which is similar to the serial fraction) and incoherence. Incoherence refers to the time spent restoring a common view of the world across different processors.
In a single CPU, incoherence penalties arise from caching. When one core changes a cache line, it tells other cores to eject that line from their caches. If they need to touch the same line, they spend time reloading it from main memory. (This is a slightly simplified description… but the more precise form still has incoherence penalty.)
Across database nodes, incoherence penalties arise from consistency and agreement algorithms. The penalty can be paid when data is changed (as in the case of transactional databases) or when the data is read in the case of eventually consistent stores.
Effect of USL
When you graph the USL as a function of number of processors, you get the green line on this graph:
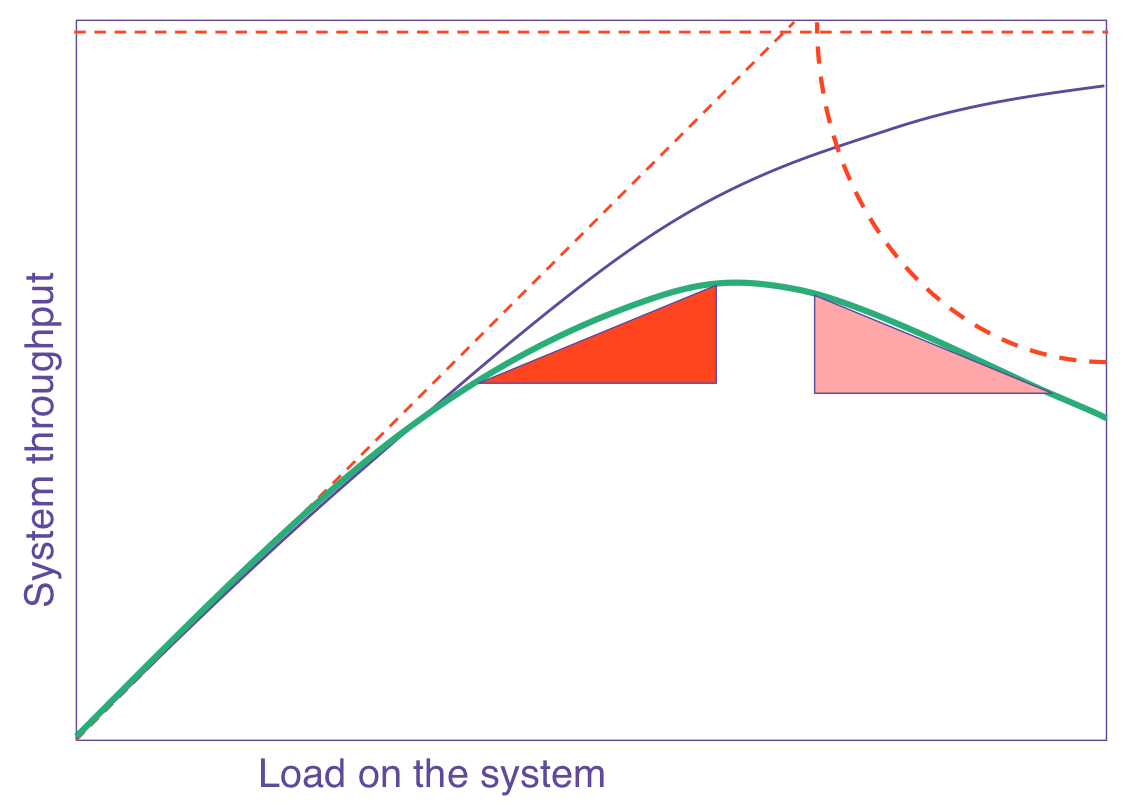 (Image from perfdynamics.com)
(Image from perfdynamics.com)
(The purple line shows what Amdahl's Law would predict.)
Notice that the green line reaches a peak and then declines. It means that there is a number of nodes that produces maximum throughput. Add more processors and throughput goes down. Overscaling hurts throughput. I've seen this in real-life load testing.
We'd often like to increase the number of processors and get more throughput. There are exactly two ways to do that:
- Reduce the serial fraction
- Reduce the incoherence penalty
USL in Teams?
Let's try an analogy. If the "job" is a project rather than a computational task, then we can look at the number of people on the project as the "processors" doing the work.
In that case, the serial fraction would be whatever portion of the work can only be done one step after another. That may be fodder for a future post, but it's not what I'm interested in today.
There seems to be a direct analog for the incoherence penalty. Whatever time the team members spend re-establishing a common view of the universe is the incoherence penalty.
For a half-dozen people in a single room, that penalty might be really small. Just a whiteboard session once a week or so.
For a large team across multiple time zones, it could be large and formal. Documents and walkthrough. Presentations to the team, and so on.
In some architectures coherence matters less. Imagine a team with members across three continents, but each one works on a single service that consumes data in a well-specified format and produces data in a well-specified format. They don't require coherence about changes in the processes, but would need coherence for any changes in the formats.
Sometimes tools and languages can change the incoherence penalty. One of the arguments for static typing is that it helps communicate across the team. In essence, types in code are the mechanism for broadcasting changes in the model of the world. In a dynamically typed language, we'd either need secondary artifacts (unit tests or chat messages) or we'd need to create boundaries where subteams only rarely needed to re-cohere with other subteams.
All of these are techniques aimed at the incoherence penalty. Let's recall that overscaling causes reduced throughput. So if you have a high coherence penalty and too many people, then the team as a whole moves slower. I've certainly experienced teams where it felt like we could cut half the people and move twice as fast. USL and the incoherence penalty now helps me understand why that was true—it's not just about getting rid of deadwood. It's about reducing the overhead of sharing mental models.
In The Fear Cycle I alluded to codebases where people knew large scale changes were needed, but were afraid of inadvertant harm. This would imply a team that was overscaled and never achieved coherence. Once lost, it seems to be really hard to re-establish. That means ignoring the incoherence penalty is not an option.
USL and Microservices
By the way, I think that the USL explains some of the interest in microservices. By splitting a large system into smaller and smaller pieces, deployed independently, you reduce the serial fraction of a release. In a large system with many contributors, the serial fraction comes from integration, testing, and deployment activities. Part of the premise for microservices is that they don't need the integration work, integration testing, or delay for synchronized deployment.
But, the incoherence penalty means that you might not get the desired speedup. I'm probably stretching the analogy a bit here, but I think you could regard interface changes between microservices as requiring re-coherence across teams. Too much of that and you won't get the desired benefit of microservices.
What to do about it?
My suggestion: take a look at your architecture, language, tools, and team. See where you spend time re-establishing coherence when people make changes to the system's model of the world.
Look for splits. Split the system with internal boundaries. Split the team.
Use your environment to communicate the changes so re-cohering can be a broadcast effort rather than one-to-one conversations.
Look at your team communications. How much of your time and process is devoted to coherence? Maybe you can make small changes to reduce the need for it.