I have a rich and multidimensional relationship with Amazon. It started back in 1996 or 1997, when it became the main supplier for my book addiction. As the years went by, I became an "Amazon Affiliate" in a futile attempt to balance out my cash flow with the company. Later, I started using AWS for cloud computing. I also claimed my author page.
Let's contemplate the data architecture needed to maintain such a set of relationships. Let's assume for the moment that Amazon were using a SQL RDBMS to hold it all. The obvious approach is something I could call the "Big Fat User Table". One table, keyed by my secret, internal user ID, with columns for all the different possible thing a user can be to Amazon. There would be a dozen columns for my affiliate status, a couple for my author page, a boolean to show I've signed up for AWS, and a bunch of booleans for each of the individual services.
Such a table would table would be an obvious bottleneck. Any DBA worth her salt would split that sucker into many tables, joined by a common key (the user ID.) New services would then just add a table in their own database with the common user ID. Let's call this approach the "Universal Identifier" design.
That would also allow one-to-many relations for some aspects. For example, when I lived in Minnesota, the state demanded that Amazon keep track of tax for each affiliate. Amazon responded by shutting down all the affiliate accounts in Minnesota. I recently moved to Florida and was able to open a new account with my new address. So I have two affiliate accounts attached to my user account.
For what it's worth, column family databases would kind of blur the lines between the Big Fat User Table and the Universal Identifier design.
We can get more flexible than the Universal Identifier, though.
You see, if we push the User ID into all the various services, that implies that the "things" that service manages can only be consumed by a User. Maneuverable architecture says we should be able to recompose services in novel configurations to solve business problems.
Instead of pushing the User ID into each service, we should just let each service create IDs for its "things" and return them to us.
For example, a Calendar Service should be willing to create a new
calendar for anyone who asks. It doesn't need to know the ID of the
owner. Later, the owner can present the calendar ID as part of a
request (usually somewhere in the URL) to add events, check dates, or
delete the calendar. Likewise, a Ledger service should be willing to
create a new ledger for any consumer, to be used for any purpose. It
could be a user, a business, or a one-time special partnership. The
calls could be coming from a long-lived application, a bit of script
hooked to a URL, or curl in a bash script. Doesn't matter.
If we've got all these services issuing identifiers, we need some way to stitch them back together. That's where the faceted identities come in. If we start from a user and follow all the related "stuff" connected to that user, it looks a lot like a graph.
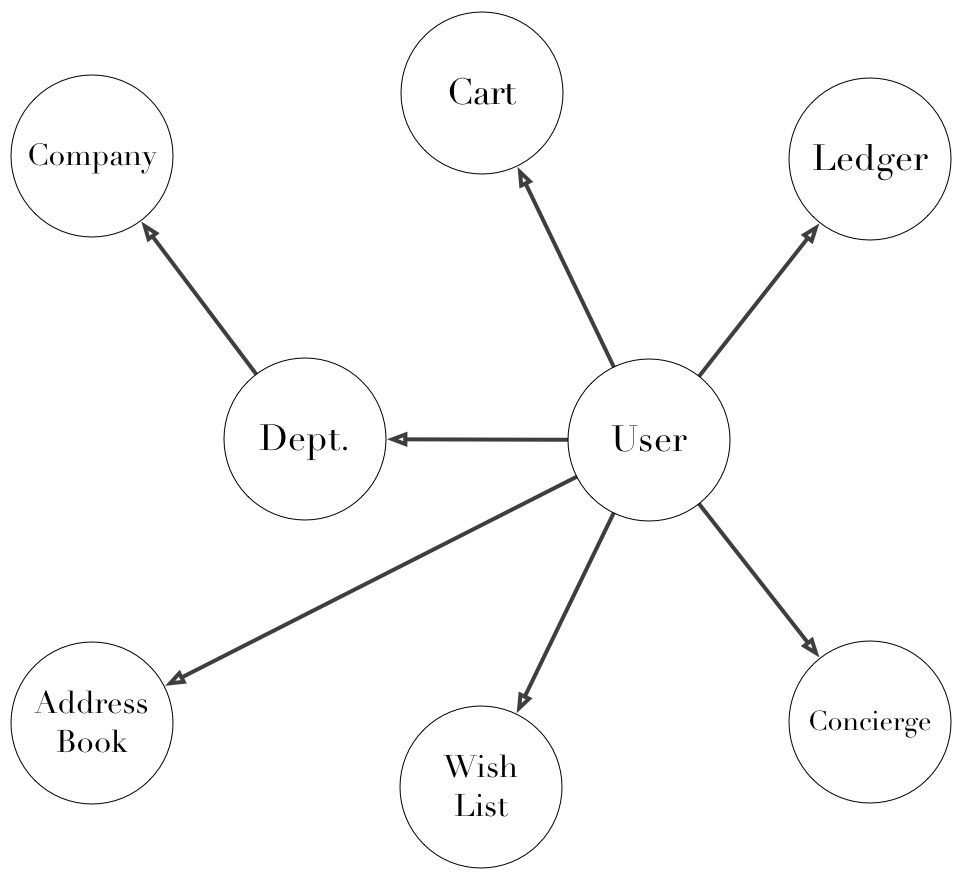
When a user logs in to the customer-facing application, that app is responsible for traversing the graph of identities, making requests to services, and assembling the response.
I hope you aren't surprised when I say that different applications may hold different graphs, with different principals as their roots. That goes along with the idea that there's no privileged vantage point. Every application gets to act like the center of its own universe.
Going Meta
If you've been schooled in database design, this probably looks a little weird. I'm removing the join keys from the relational databases. (Some day soon I need to write a post addressing a common misconception: that "relational" databases got their name because they let you relate tables together.)
The key issue I'm aiming at is really about logical dependencies in the data. Foreign key relationships are a policy statement, not a law of nature. Policies change on short notice, so they should be among the most malleable constructs we have. By putting that policy in the bottommost layer of every application, we make it as hard as possible to change!
We can think of a hierarchy of "looseness" in relationships:
- Two ideas, stored in one entity: As coupled as it gets. Neither idea can be used without the other. (An "entity" here can be a table or link data resources with URLs. It's not about the storage, but about the required relationship.)
- Two ideas, two entities, one-to-one: Still, both ideas must be used together.
- Two ideas, two entities, one-to-one optional: Now we can at least decide whether the second item is needed with the first.
- Two ideas, two entities, one-to-many: This admits that the second idea may come in different quantities than the first.
- Two ideas, two entities, many-to-many: Much more flexible! Both ideas can be combined in differing quantities as needed. However, this still requires that these ideas are only used together with each other. In other words, if ideas X and Y have a many-to-many relationship, I don't get to reuse idea X together with idea A.
- Two ideas, externalized relationship: This is the heart of faceted identities. Ideas X and Y can be completely independent. Each can be used together by other applications.
Interface Segregation Principle
The "I" in SOLID stands for Interface Segregation Principle. It says that a client should only depend on an interface with the minimum set of methods it needs. An object may support a wide set of behavior, but if my object only needs three of those behaviors, then I should depend on an interface with precisely those three behaviors. (One hopes those three make sense together!)
This has an application when we use faceted identies as well. Sometimes we have a very nice separation where the facets don't need to interact with each other, only the application interacts with all of them. More often though, we do need to pass an identifier from one kind of thing into another. That's when the contract becomes important. If service Y requires a foreign identifier "X" to perform an action, then it needs to be clear about what it will do with "X". It's up to the calling application to ensure that the "X" it passes can perform those actions.
Summary
Maneuverability is all about composing, recomposing, and combinging services in novel configurations. One of the biggest impediments to that is relationships among entities. We want to make those as loose as possible by externalizing the relationships to another service. This allows entities to be used in new ways without coordinated change across services. Furthermore, it allows different applications to use different relationship graphs for their own purposes.