People who don't live in operations can carry some funny misconceptions in their heads. Some of my personal faves:
- Just add some servers!
- I want a report of every configuration setting that's different between production and QA!
- We're going to make sure this (outage) never happens again!
I've recently been reminded of this during some discussions about disaster recovery. This topic seems to breed misconceptions. Somewhere, I think most people carry around a mental model of failover that looks like this:
That is, failover is essentially automatic and magical.
Sadly, there are many intermediate states that aren't found in this mental model. For example, there can be quite some time between failure and it's detection. Depending on the detection and notification, there can be quite a delay before failover is initiated at all. (I once spoke with a retailer whose primary notification mechanism seemed to be the Marketing VP's wife.)
Once you account for delays, you also have to account for faulty mechanisms. Failover itself often fails, usually due to configuration drift. Regular drills and failover exercises are the only way to ensure that failover works when you need it. When the failover mechanisms themselves fail, your system gets thrown into one of these terminal states that require manual recovery.
Just off the cuff, I think the full model looks a lot more like this:
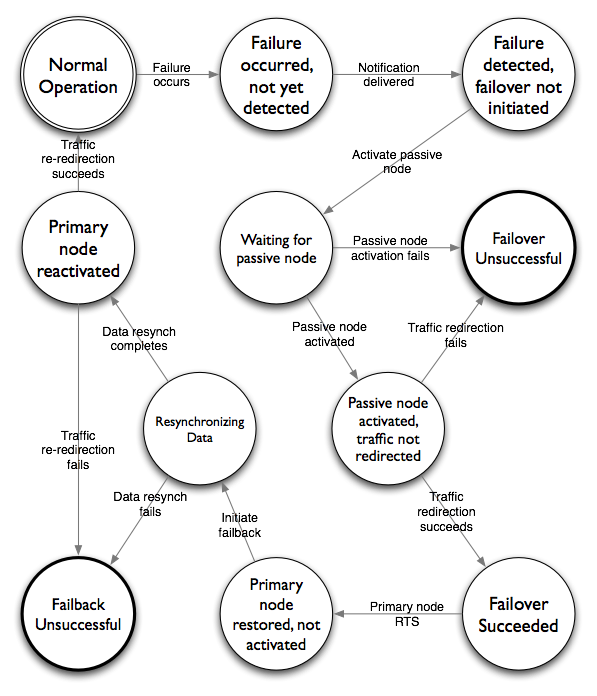
It's worth considering each of these states and asking yourself the following questions:
- Is the state transition triggered automatically or manually?
- Is the transition step executed by hand or through automation?
- How long will the state transition take?
- How can I tell whether it worked or not?
- How can I recover if it didn't work?