Here's a syllogism for you:
- Every technical review process is a queue
- Queues are evil
- Therefore, every review process is evil
Nobody likes a review process. Teams who have to go through the review look for any way to dodge it. The reviewers inevitably delegate the task downward and downward.
The only reason we ever create a review process is because we think someone else is going to feed us a bunch of garbage. They get created like this:
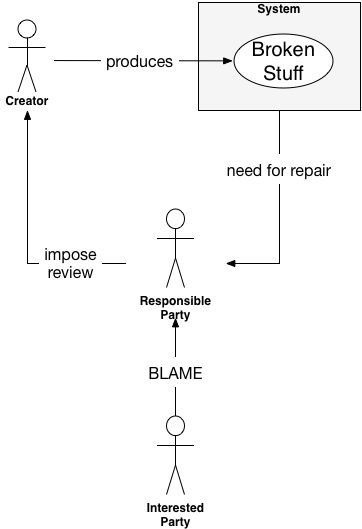
It starts when someone breaks a thing that they can't or aren't allowed to fix. The responsibility for repair goes to a different person or group. That party shoulders both responsibility for fixing the thing and also blame for allowing it to get screwed up in the first place.
(This is an unclosed feedback loop, but it is very common. Got a separate development and operations group? Got a separate DBA group from development or operations? Got a security team?)
As a followup, to ensure "THIS MUST NEVER HAPPEN AGAIN" the responsible party imposes a review process.
Most of the time, the review process succeeds at preventing the same kind of failure from recurring. The resulting dynamic looks like this:
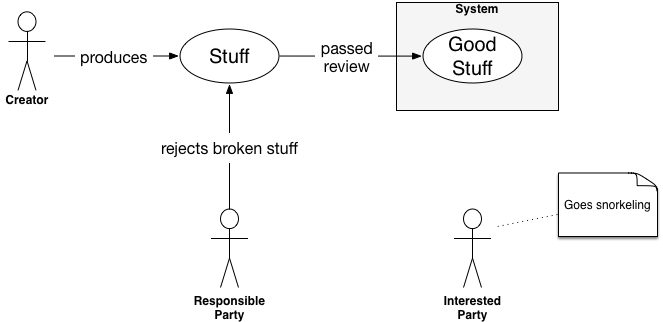
The hidden cost is the time lost. Every time that review process has to go off, the creator must prepare secondary artifacts: some kind of submission to get on the calendar, a briefing, maybe even a presentation. All of these are non-value-adding to the end customer. Muda. Then there's the delay on the review meeting or email itself. Consider that there is usually not just one review but several needed to get a major release out the door and you can see how release cycles start to stretch out and out.
Is there a way we can get the benefit of the review process without incurring the waste?
Would I be asking the question if I didn't have an answer?
The key is to think about what the reviewer actually does. There are two possibilities:
- It's purely a paperwork process. I'll automate this away with a script that makes PDF and automatically emails it to whomever necessary. Done.
- The reviewer applied knowledge and experience to look for harmful situations.
Let's talk mostly about the latter case. A lot of our technology has land mines. Sometimes that is because we have very general purpose tools available. Sometimes we use them in ways that would be OK in a different situation but fail in the current one. Indexing an RDBMS schema is a perfect example of this.
Sometimes, it's also because the creators just lack some experience or education. Or the technology just has giant, truck-sized holes in it.
Whatever the reason, we expect that the reviewer is adding intelligence, like so:
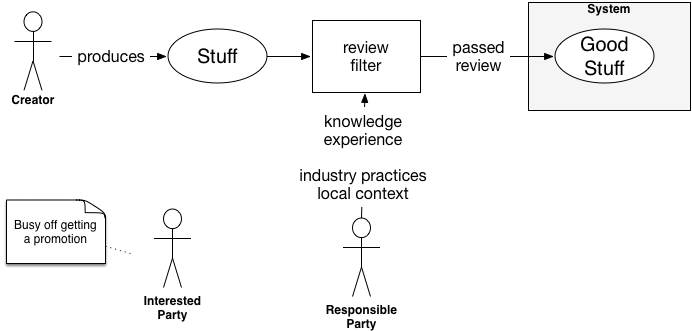
This benefits the system, but it could be much better. Let's look at some of the downsides:
- Throughput is limited to the reviewer's bandwidth. If they truly have a lot of knowledge and experience, then they won't have much bandwidth. They'll be needed elsewhere to solve problems.
- The creator learns from the review meetings… by getting dinged for everything wrong. Not a rewarding process.
- It is vulnerable to the reviewer's availability and presence.
I'd much rather see the review codify that knowledge by building it into automation. Make the automation enforce the practices and standards. Make it smart enough to help the creator stay out of trouble. Better still, make it smart enough to help the creator solve problems successfully instead of just rejecting low quality inputs.
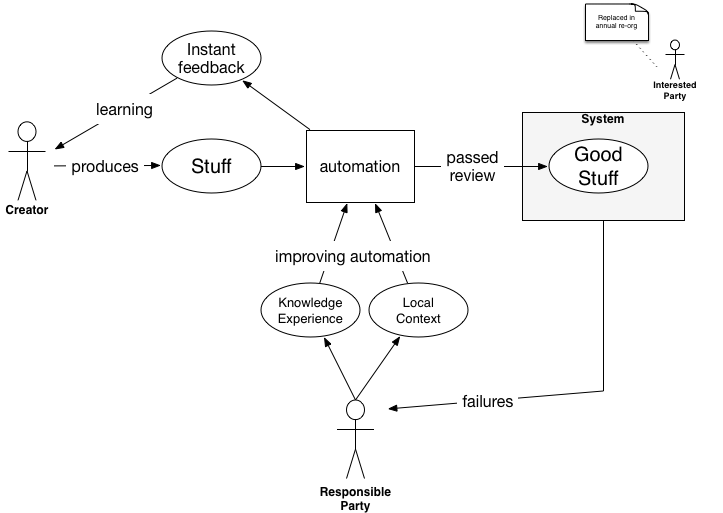
With this structure, you get much more leverage from the responsible party. Their knowledge gets applied across every invocation of the process. Because the feedback is immediate, the creator can learn much faster. This is how you build organizational knowledge.
Some technology is not amenable to this kind of automation. For example, parsing some developer's DDL to figure out whether they've indexed things properly is a massive undertaking. To me, that's a sufficient reason to either change how you use the technology or just change technology. With the DDL, you could move to a declarative framework for database changes (e.g., Liquibase). Or you could use virtualization to spin up a test database, apply the change, and see how it performs.
Or you can move to a database where the schema is itself data, available for query and inspection with ordinary program logic.
The automation may not be able to cover 100% of the cases in general-purpose programming. That's why local context is important. As long as there is at least one way to solve the problem that works with the local infrastructure and automation, then the problem can be solved. In other words, we can constrain our languages and tools to fit the automation, too.
Finally, there may be a need for an exception process, where the automation can't decide whether something is viable or not. That's a great time to get the responsible party involved. That review will actually add value because every party involved will learn. Afterward, the RP may improve the automation or may even improve the target system itself.
After all, with all the time that you're not spending in pointless reviews, you have to find something to do with yourself.
Happy queue hunting!