My last post on the subject of inverted ownership felt a bit abstract, so I thought I might illustrate it with a typical scenario.
In this first figure, we see a newly-extracted Catalog service,
freshly factored out of the old monolithic application. It's part of
the company's effort to become more maneuverable. We don't know, or
particularly care, what storage model it uses internally. From the
outside, it presents an interface that looks like "SKUs have
attributes".

All seems well. It looks and smells like a microservice: independently deployable, released on its own schedule by a small autonomous team.
The problem is what you don't see in the picture: context. This service has one "universe" of SKUs. It doesn't serve catalogs. It serves one catalog. The problem becomes evident when we start asking what consumers of this service would want. If we think of the online storefront as the only consumer then it looks fine. Ask around a bit, though, and you'll find other interested parties.
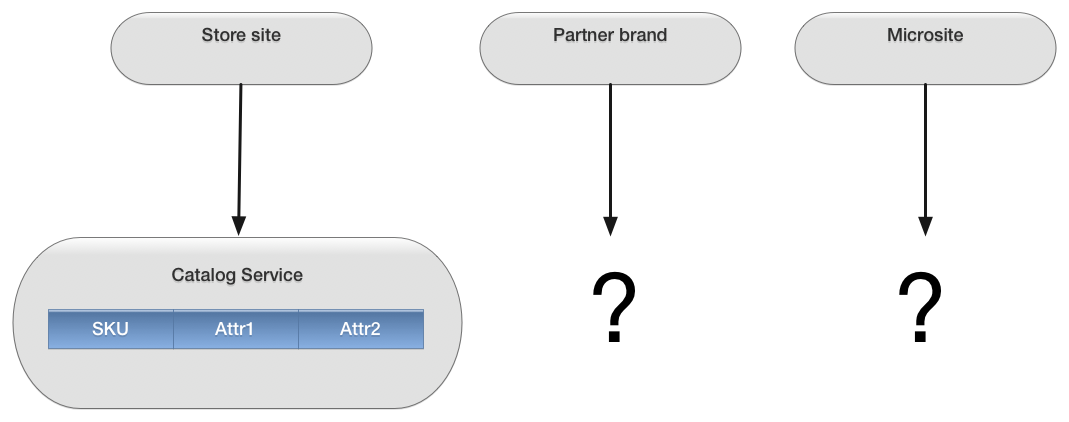
While IT toils to get down to a single source of record for product information, the wheelers and dealers in the business are out there signing up partners, inventing marketing campaigns, and looking into new lines of business. Pretty much all of those are going to screw around with the very idea of "the catalog".
Maneuverability demands that we can combine and recombine our services in novel ways. What can we do with this catalog service that would let it be reused in ways that the dev team didn't foresee?
Instancing might be one approach… multiple deployments from the same code base. High operational overhead, but it's better than being stuck.
I prefer to make the context explicit instead.
Zero, One, Many
There's an old saying that the only sensible numbers are zero, one, and infinity. One catalog isn't enough, so the right number to support is "infinity." (Or some resource-constrained approximation.)
What does it take? All we have to do is make catalog service create catalogs for anyone who asks. Any consumer that needs a catalog can create one. That might be a big, sophisticated online storefront. But it could be someone using cURL to manually construct a small catalog for a one-off marketing effort. The catalog service shouldn't care who wants the catalog or what purpose they are going to put it to.
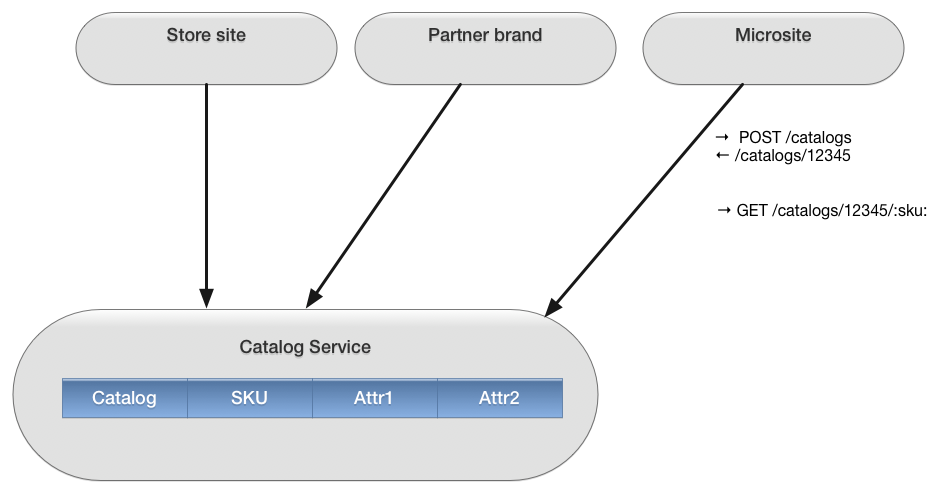
Of course, this means that subsequent requests need to identify which catalog the item comes from. Good thing we're already using URLs as our identifiers.
Considerations
There are some practical issues (and maybe objections) to address.
First, does this mean that the SKUs are duplicated across all those catalogs? Not necessarily. We're talking about the interface the service presents to consumers. It can do all kinds of deduplication internally. See my post about the immutable shopping cart for some ideas about deduplication and "natural" identifiers.
Second, and trickier, how do the SKUs get associated to the catalog? Does each microsite and service need to populate its own catalog? Can it just cherry-pick items from a "master" catalog?
You can probably guess that I don't much like the idea of a "master" catalog. Instead, we would populate a newly-minted catalog by feeding it either item representations (serialized data in a well-known format) or better yet, hyperlinks that resolve to item representations.
How about this: make the service support HTML, RDFa, and a standardized microformat as a representation. Then you just feed your catalog service with URLs that point to HTML. Those can come from a catalog of your own, an internal app for cleansing data feeds, or even a partner or vendor's web site. Now you've unified channel feeds, data import, and catalog creation.
Third, is it really true that just anyone can create a catalog? Doesn't this open us up to denial-of-service attacks wherein someone could create billions of catalogs and goop up our database? My response is that we don't ignore questions of authorization and permission, but we do separate those concerns. We can use proxies at trust boundaries to enforce permission and usage limits.
Conclusion
When you make the context explicit, you allow a service to support an arbitrary number of consumers. That includes consumers that don't exist today and even ones you can't predict. Each service then becomes a part that you can recombine in novel ways to meet future needs.